








Can We Trust an AI Agent to Execute Tests?
AI Lynqa


Bruno Legeard
Published on 05.05.26
- AI can be wrong. The question is how the risk is controlled.
- AI agent to execute tests: What can go wrong?
- Pillar 1 - Measuring reliability
- Pillar 2 - Human/AI clarification and knowledge acquisition
- Pillar 3 - Transparency of actions and explanation of results
- How to run a first evaluation in Xray
- So can We Trust an AI Agent to Execute Our Tests?
The three pillars of trustworthy agentic AI test execution in Xray: measurable reliability, human control, and transparent evidence.
“An AI test execution agent? How can I trust an AI agent to execute tests when I know AI is not always reliable?”
This is often the first question QA teams ask when they discover agentic AI test execution. And it is the right question.
In previous articles, we introduced the role of agentic AI test execution in the Xray ecosystem and explained how it complements AI-assisted test script generation across the testing lifecycle. In particular, we showed how Lynqa for Xray executes existing manual and Gherkin tests directly from Xray, while Xray’s AI-assisted scripting helps automation engineers generate code for stable regression scenarios.
Want to learn more about Lynqa? Go to the Lynqa page
In this article, I want to focus on reliability.
Not reliability as a marketing promise, but reliability as something a QA team can measure, review, and improve in its own Jira/Xray environment.
Lynqa, developed by Smartesting, brings agentic test execution directly into Xray. It enables QA teams to execute their existing manual or Gherkin tests without scripts, locators, or code, and to review the execution evidence inside their usual Xray workflow.
The true question is not whether we can blindly trust an AI agent; the answer must be no.
Instead, we should ask: can we measure the agent’s behavior, understand its decisions, and maintain human control where it is essential?
That is the foundation of trustworthy agentic AI test execution.
AI can be wrong. The question is how the risk is controlled.
Generative AI models can hallucinate. They can produce an answer that looks plausible but is wrong. This is not an accidental defect: it is a consequence of how probabilistic models work.
That does not prevent AI from delivering real value in software testing. But the type of risk depends strongly on the use case.
When generative AI is used to improve user stories or generate test cases, the main risks are usually:
- Irrelevant output: the reformulation does not reflect the business need, or the generated tests do not make sense for the application.
- Incomplete output: important acceptance criteria are missing, or key test situations are not covered.
In these situations, the root cause is often weak context engineering. Whatever model you use, it needs a precise, structured, and relevant project context to produce useful results.
With agentic AI test execution, the risk is different.
Why? Because the AI agent acts on the system under test. It not only generates content. It executes, observes, interprets, and produces a verdict.
That changes the trust equation.
AI agent to execute tests: What can go wrong?
The error patterns are not unique to AI.
A human QA tester and an AI agent to execute tests face similar types of execution risks. Both may:
- Fail to perform an action requested by the scenario
The cause may be familiar: incomplete environment setup, missing test data, unavailable action, or difficulty understanding how to perform a specific interaction. For AI agents, this was a major limitation a year ago. It has improved considerably with better tools, stronger visual perception, and better reasoning capabilities.
- Have doubts about the result and produce a false positive
A false positive happens when the test execution reports a defect, but the software is actually working correctly. For example, the actual message is close to the expected message, but not identical. The agent marks the step as failed, while a human reviewer later concludes that the behavior is acceptable.
- Miss an issue and produce a false negative
A false negative happens when the test execution reports that everything is fine, but there is actually a defect. This is the most concerning case: the test passes when it should have failed. Manual testers know this risk well. Some defects are subtle. Expected results can be ambiguous. Some situations are easy to misinterpret. An AI test execution agent can encounter the same difficulty.
This is why trust in agentic AI test execution must be built on facts, not promises.
At Smartesting, we see three pillars for building that trust with Lynqa for Xray:
- Measured reliability
- Human/AI clarification and reusable knowledge
- Transparency of actions and explanation of results
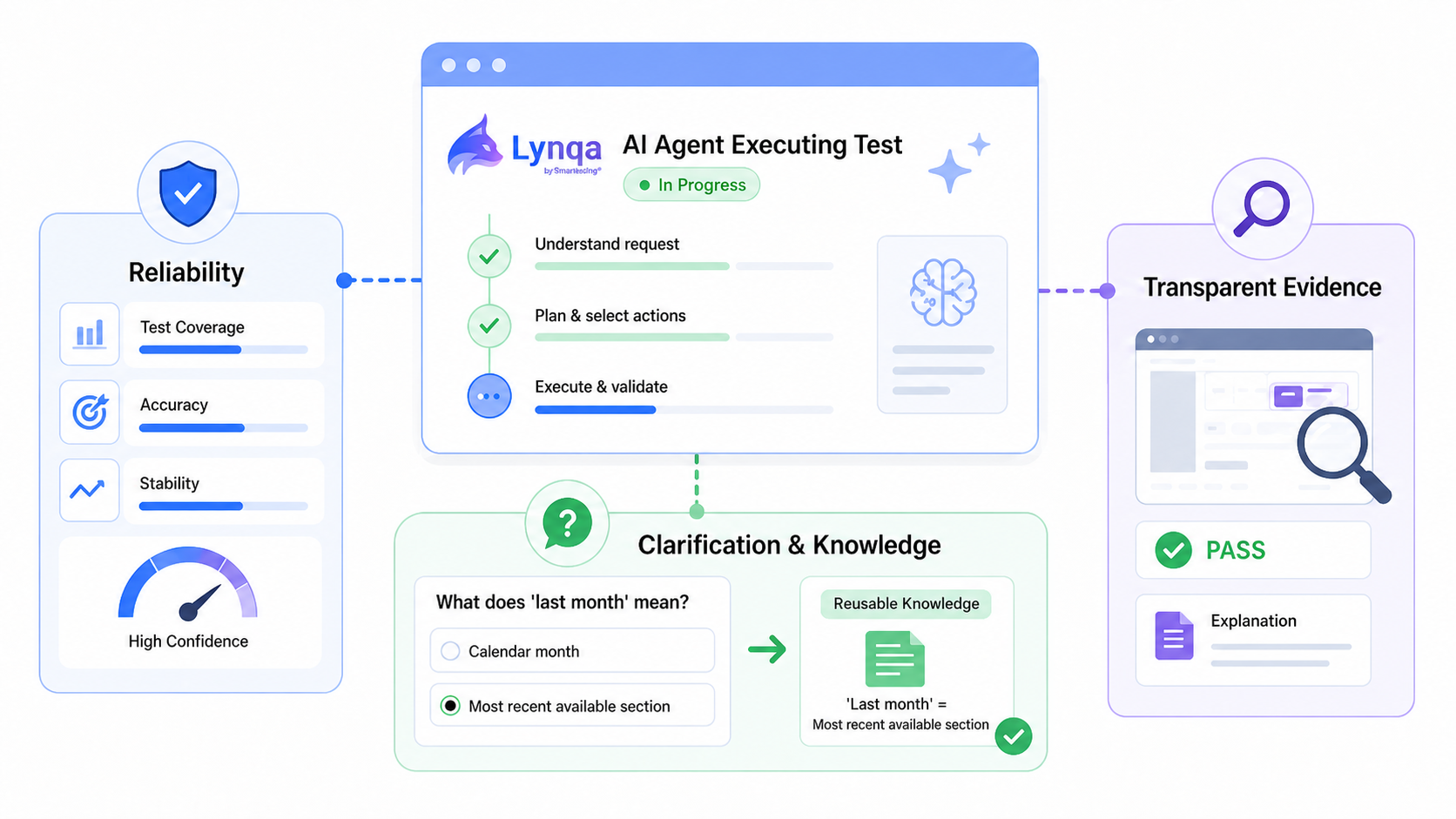
Pillar 1 – Measuring reliability
Evaluating an AI test execution agent requires three components:
- Representative test sets
- Automated evaluation metrics
- An execution infrastructure that makes results repeatable
In other words, benchmarking.
One important point: there is currently no publicly available reference benchmark dedicated specifically to AI test-execution agents.
The closest category is the family of “computer-use” benchmarks. These evaluate the ability of general-purpose AI agents to interact autonomously with applications, as a user would. They do not measure software testing directly, but they provide a useful signal about the maturity of agents that interact with real applications.
For a test execution agent, the evaluation has to go further.
It is not enough to know whether the agent eventually reaches the right screen. We also need to understand whether it respected the test case’s intent, interpreted the expected result correctly, and whether its verdict is trustworthy.
For Lynqa for Xray, we pay particular attention to two questions:
- Did the agent respect the test intent expressed in the Xray scenario?
- Did the agent avoid false negatives when checking expected results?
This distinction matters. An agent may reach the right final state for the wrong reasons. For test execution, the path matters as much as the outcome.
On our internal benchmarks at the Smartesting AI Lab, built and continuously enriched across representative web and desktop applications, Lynqa’s per-step execution reliability is above 85%.
This means that, out of 100 executed test steps, more than 85 are assessed correctly, with the right verdict and a meaningful explanation. The score includes verdict correctness, explanation quality, false positives, false negatives, and cases where the agent cannot yet perform the requested action.
This level is high enough to justify serious evaluation in real QA workflows. It is not a claim that the agent is perfect.
Errors, while infrequent, typically belong to one of two main groups:
- Missing execution capabilities
- Misinterpretation of ambiguous expected results
This leads to the second pillar.
Want to assess whether you can trust an AI Agent to Execute Tests in your own Xray project?
Start with a small set of representative test cases and compare Lynqa’s step-by-step evidence with your QA team’s expected verdicts with 10 free execution credits.
Pillar 2 – Human/AI clarification and knowledge acquisition
A trustworthy AI test execution agent should not pretend to know everything.
It should detect when it is uncertain, ask for clarification, and learn from the answer.
In Lynqa for Xray, this principle is central to how we think about supervised agentic execution. The agent should execute autonomously when the instruction is clear, but it should involve the QA tester when the interpretation of a step is ambiguous.
In practice, this works through an observation mechanism that analyzes the execution trace and the agent’s reasoning. When significant uncertainty is detected, the agent can prepare a request for the human QA tester.
The human answer can lead to:
- The creation of reusable knowledge for the agent
- A suggested reformulation of the test step
- Or both
A concrete example
A test case checks a website section called “Most read articles.”
One step asks the agent to verify the “most read articles from last month.”
The test runs in early April 2026. On the website, however, the most recent monthly section available is February 2026.
So what does “last month” mean here?
Does it mean March 2026, the calendar month before April? Or does it mean the most recent monthly section actually available on the page?
This is the kind of ambiguity a human tester would notice. A good AI test-execution agent should notice it, too.
The agent raises a clarification request. The QA tester answers:
“Last month = the most recent section available on the page.”
From that answer, the agent can create reusable knowledge:
“When checking content corresponding to ‘last month,’ use the most recent month actually available on the page, not necessarily the calendar month before the current date.”
The scope of this knowledge can be defined at the step, scenario, or test suite level. This ability to acquire knowledge lets the agent learn the implicit rules, conventions, and preferences of the QA team.
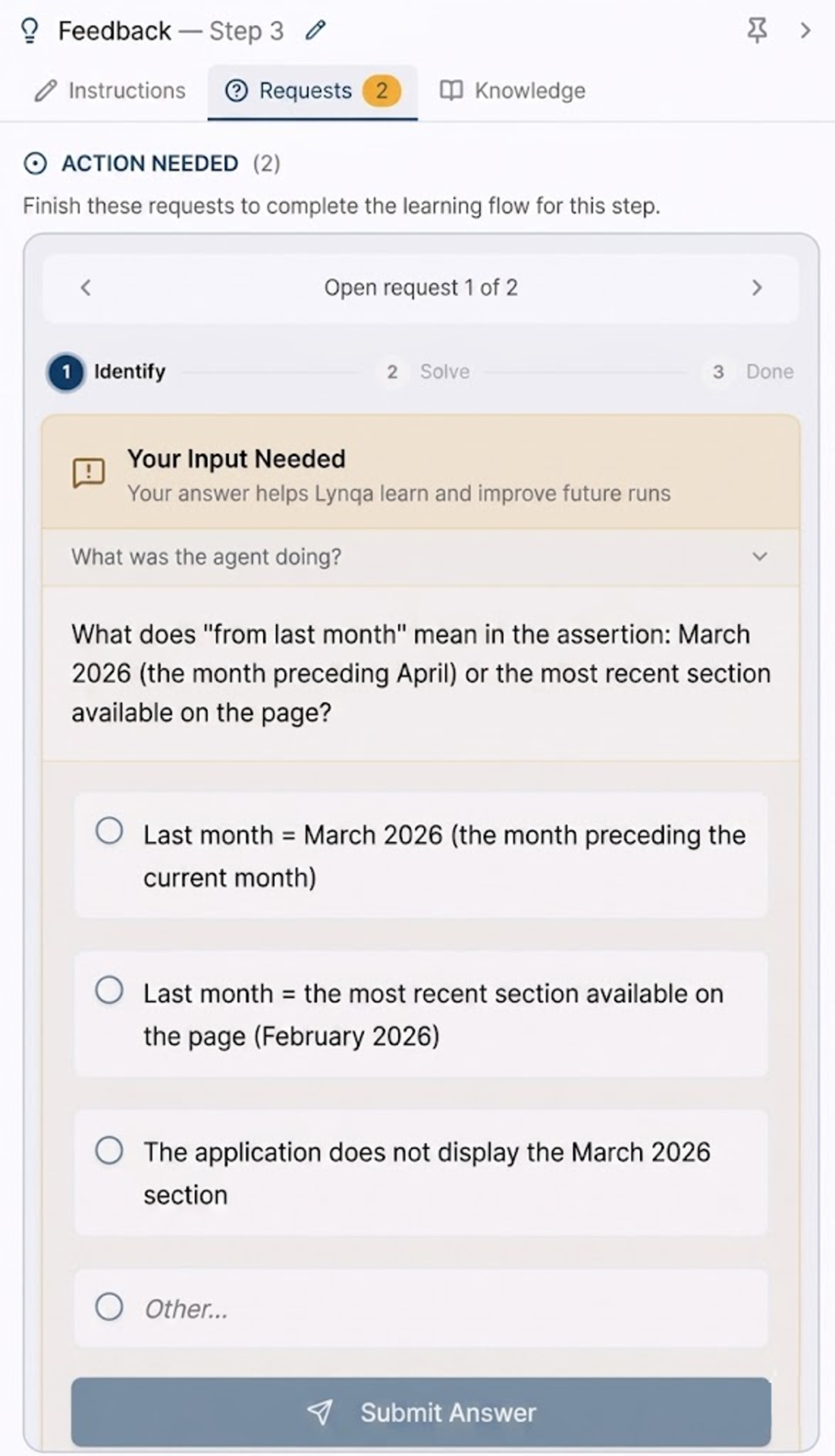
Figure: The interface for clarifying and acquiring knowledge based on the example given.
For a QA team, this changes three things:
- Ambiguous situations are detected.
- Human intervention is requested only when needed.
- The agent’s behavior improves over time.
On our Lynqa Lab benchmarks, the human/AI clarification loop and knowledge acquisition address more than 90% of detected uncertainty cases, eliminating most misinterpretations caused by ambiguous instructions.
Some cases will still require review. That is expected in a supervised execution model.
The relevant question is not whether the agent is perfect. It is whether the value gained from automated execution outweighs the cost of human control.
Note: The human/AI clarification loop and knowledge acquisition mechanisms described here are currently in experimental validation at the Smartesting AI Lab with pilot QA teams, ahead of rollout in Lynqa for Xray.
Pillar 3 – Transparency of actions and explanation of results
An AI test execution agent can now run long functional scenarios, flag uncertainty, and reuse project-specific knowledge.
But it must remain under the control of the human QA tester.
The final decision on whether to accept an execution result is a human responsibility.
A trustworthy agent must therefore make its activity readable, verifiable, and auditable. When reviewing an execution report, the QA tester should be able to answer five questions for every step:
- Where did the agent navigate?
- What actions did it perform?
- What did it observe on the screen?
- Why did it conclude PASS or FAIL?
- What evidence supports the verdict?
This is why evidence is so important in Lynqa for Xray.
Screenshots document actions and observed states. Step-by-step execution logs make the path readable. Explanations help the tester understand how the verdict was produced.
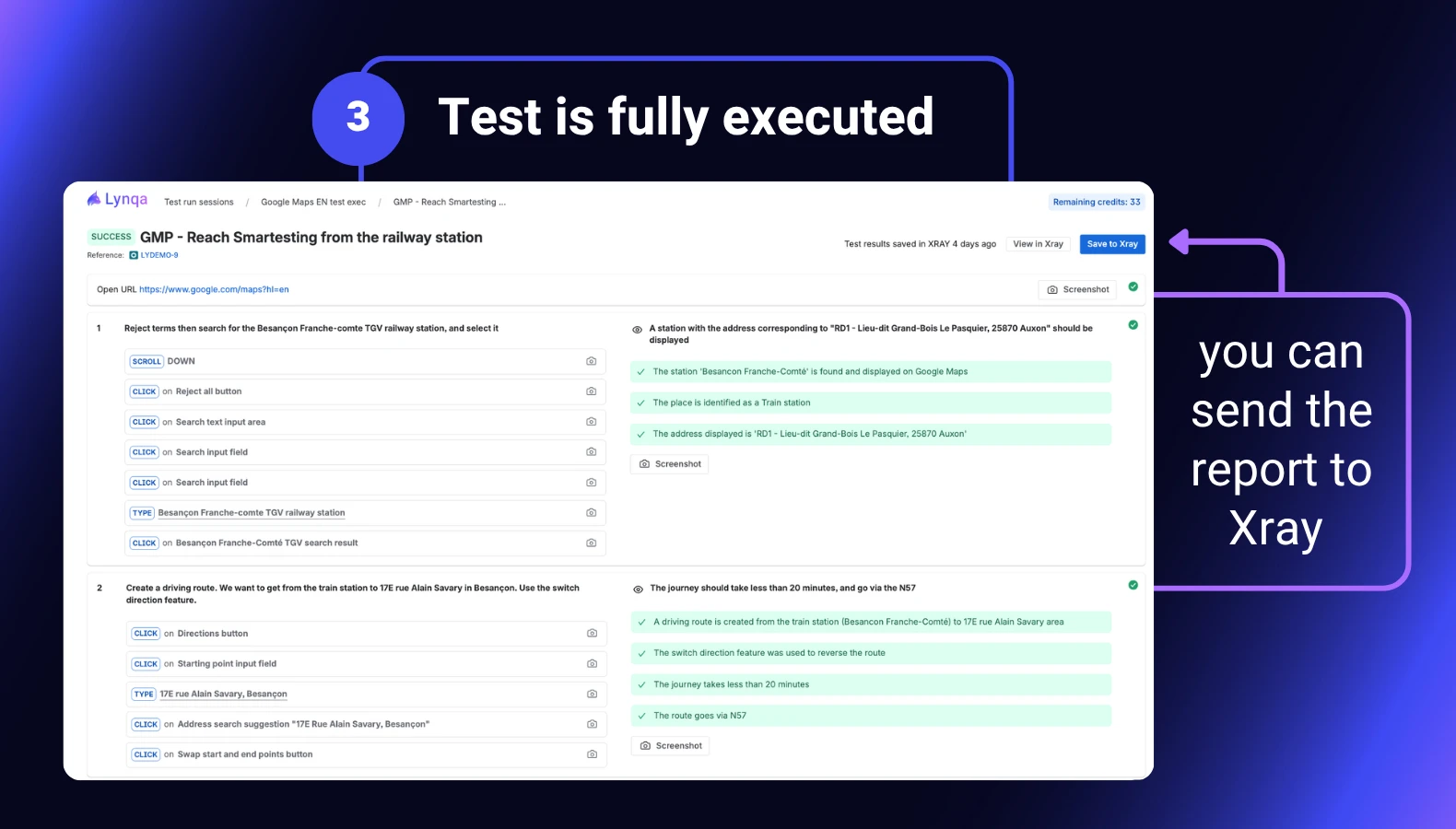
In case of failure, the agent’s comment must be even more explicit. It should help the tester distinguish between:
- A real defect
- A misinterpretation
- A limitation in execution
- An issue with test data or environment setup
This requirement for transparency is not specific to AI.
It already existed when teams outsourced manual test execution. QA teams expected detailed tracking, evidence, and the ability to review each step in case of doubt.
With an AI test execution agent, the need is the same.
The difference is that the evidence can be collected automatically and made available directly inside the Xray workflow.
How to run a first evaluation in Xray
Reliability cannot be evaluated solely by reading benchmark numbers, including those shared above.
A QA team needs to see how an AI test-execution agent behaves in its own application, using its own test cases and its own definition of acceptable risk.
A simple way to start is to run a small evaluation of agentic AI test execution inside Xray.
This is also a useful exercise for improving your test repository. Ambiguous expected results, implicit business rules, missing test data, and unclear navigation instructions become visible quickly when an agent tries to execute the test as written.
Agentic execution not only automates test runs. It also reveals where test cases require clarification.
This is the idea behind Lynqa for Xray: execute your existing Xray tests without rewriting or scripts while keeping step-by-step proof directly in Xray.
For teams using Jira Cloud and Xray, the native integration matters in practice:
- The test case stays in Xray.
- The execution is launched from Xray.
- The execution evidence is reviewed in Xray.
To decide whether your team can trust an AI Agent to Execute Tests, start with a focused evaluation.
A few practical recommendations:
1. Pick a representative subset of your test suites.
2. Cover different complexity levels: happy paths, edge cases, and end-to-end scenarios.
3. Review the failures, not just the pass rate.
4. Identify whether each failure comes from the application, the test data, the environment, the test wording, or the agent.
5. Use the review to improve both the test repository and the agent’s reusable knowledge.
The failures are often the most useful part of the evaluation. They reveal ambiguous expected results, missing test data, unclear navigation steps, or implicit business rules.
So can We Trust an AI Agent to Execute Our Tests?
In conclusion, trust is built through measurement, evidence, and control.
The development of agentic AI test execution has progressed quickly to the point where it is now ready for production. It is now advanced enough for QA teams to take it seriously and deploy it in their projects, provided it remains measurable, transparent, and supervised.
Lynqa executes existing manual test cases and Gherkin scenarios without modification, reveals the evidence step by step, highlights ambiguity when necessary, and maintains the QA tester’s control.
If your team already uses Xray on Jira Cloud and wants to evaluate whether it can trust an AI Agent to Execute Tests, a good first step is to select a representative sample of tests, run them with Lynqa, and carefully review any failures.
Trust starts with evidence, not promises.
Stay tuned!

AI Test Automation in Xray: Two Ways, Two Benefits, One Lifecycle
AI Lynqa
“AI for test automation” covers several very different things. In the Jira/Xray ecosystem specifically, two approaches are…
Read the article

Lynqa for Xray Is Officially Out of Beta: Go for Agentic AI Test Execution
AI Lynqa
Lynqa for Xray is an AI agent for manual test execution. It retrieves manual or Gherkin tests…
Read the article

Manual Testing Isn’t dead: Why human testers matter more than ever in the age of AI
AI Lynqa Testing
Introduction For more than fifteen years, a prediction has regularly surfaced in the software industry : manual…
Read the article