









How Hexagonal Architecture made our developer’s life better
Dev
Hexagonal Architecture is great, did you even doubt it? Let’s focus on the benefits provided by this approach and how it applies to real use cases.
Hexagonal architecture is not a brand-new design pattern (it was proposed in 2005 by Alistair Cockburn). There are plenty of resources available about this.
In this post, we will not cover the principles of Hexagonal Architecture, but more the benefits we get from it.
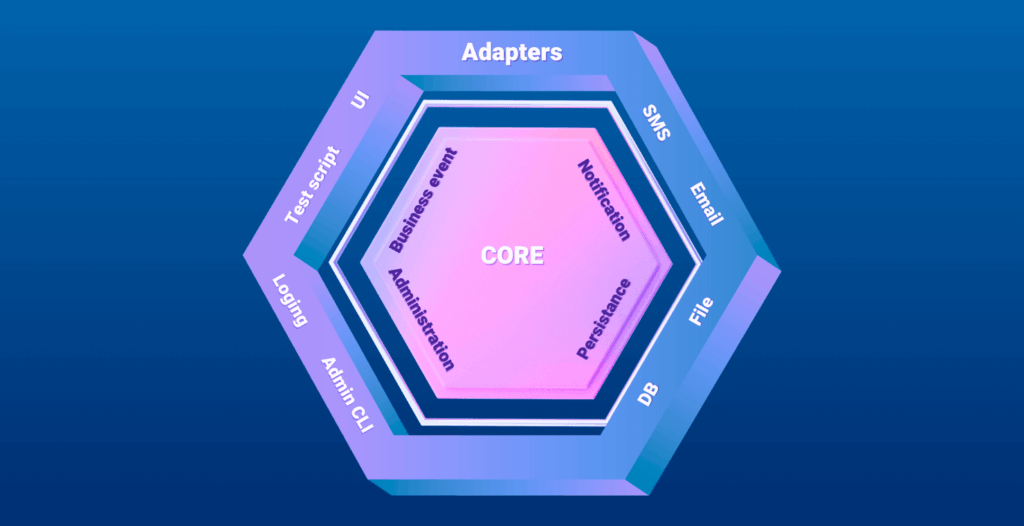
A brief explanation of Hexagonal Architecture
The main idea behind Hexagonal architecture is that you isolate your business logic in the “core”. The communication from and out of the core is done through “adapters”. They are linked to the core through “ports” (hence the original name of the pattern: “Ports and Adapters”).
I tend to find examples way easier to understand a concept. So let’s have a look at the Http endpoint below that allows a user to sign-up on a platform:
TypeScript
export async function register(req: HttpRequest, res: HttpResponse) {
const { email, password } = req.body
const user = UserModel.findByEmail(email)
if (user) return res.status(409).json({error: 'email_already_used'})
if (password.length < 8) return res.status(422).json({error: 'password_too_short'})
const user = await UserModel.create(email, password)
const jwtToken = jwt.sign({email}, SOME_SECRET)
return res.status(201).json({user, authentication: jwtToken})
}Code Issues: Mixing Business, HTTP, Data, and Authentication Logic
Although this should work pretty fine (despite the questionable choices relative to password security), there are quite a few issues about this code.
The first and most important one is that it mixes:
- business logic (a user email must be unique, a password must be at least 8 characters long),
- HTTP logic (extracting the data from the request and sending back an HTTP status),
- data logic (querying the existing users and creating a new one),
- authentication logic (the authentication is provided by a JWT token).
The second issue is that mixing logic levels makes code difficult to test. To validate the business rules, you have to trigger the code using the full HTTP stack. Or possibly mock the request and response object and have a test database to store the data. A more realistic example would certainly involve sending an email with a link to validate the signup. So we’d also need to ensure the email has been correctly sent.
The third issue is that this code is tied to some technological choices. What if we want to enable login using something else than an HTTP endpoint? What if we change the database system? … If we decide to use another authentication system than JWT? Adopting a Hexagonal Architecture approach could help to separate the business logic from the technical details. It could also enable easier testing and adaptability to different technologies and interfaces.
If we adhere to the principle of Hexagonal Architecture, we will split this code into multiple parts.
- the core function: it takes care of the business logic
- an HTTP adapter: it covers the
HTTPlogic part - an authentication adapter: it handles the
JWTlogic - user adapter: it manages the model and the database
Now, after splitting, our endpoint would look something like this (obviously, in multiple files 😉 ):
TypeScript
// The HTTP adapter
export async function registerHttpHandler(req: HttpRequest, res: HttpResponse) {
const { email, password } = req.body
const adapters = getAdapters()
const registerResponse = await register(email, password, adapters)
const status = httpStatusFromRegisterResponse(registerResponse)
return res.status(status).json(registerResponse)
}
function httpStatusFromRegisterResponse(registerResponse: RegisterResponse) {
switch (registerResponse.error) {
case RegisterError.email_already_used: return 409;
case RegisterError.password_too_short: return 422;
default: return 201
}
// The core function
export async function register(
email: string,
password: string,
{ authenticationAdapter, userManager }: Adapters
): RegisterResponse {
const user = await userManager.findByEmail(email)
if (user) return {error: RegisterError.email_already_used}
if (password.length < 8 ) return {error: RegisterError.password_too_short}
const user = await userManager.create(email, password)
const authentication = await authenticationAdapter.authenticate(user)
return {user, authentication}
}
export type Adapters {
authenticationAdapter: IAuthenticationAdapter,
userManager: IUserManager
}
export class JWTAuthenticationAdapter implements IAuthenticationAdapter {
authenticate(user: User) {
return jwt.sign({email: user.email}, SOME_SECRET)
}
}
export class UserManager implements IUserManager {
findByEmail: async (email: string) {
return UserModel.findByEmail(email)
}
create(email: string, password: string) {
return UserModel.create(email, password)
}
}Now that we have split up our code, each block of code (class or function) has a single responsibility:
registerHttpHandlerextracts the data from the request, delegates the business logic to the core function, and translates the result to anHTTPresponse.registertakes care of the business logic. It delegates authentication logic to the Authentication adapter and the User storage/querying logic to theUserManager.
Let’s dive a bit more in the benefits we get from this approach.
Simplify development
Breaking code into smaller pieces with a single responsibility makes it easier to read and write.
When I need to review code or debug an issue, I follow a systematic approach. First, I check the core function, which contains all the business logic. Then, I look at the data adapters to see how data is added or extracted from the database. Finally, I review the controllers to understand how data is extracted from the HTTP requests.
To be fair, it can be a bit puzzling at the beginning to have the code split into numerous files. Reading the first example is quite simple, and everything can be read at once. But knowing where the code should be makes it easier to find bugs and wrongly implemented rules.
In my opinion, splitting the responsibilities across multiple entities (functions, classes or whatever else) shows its benefits while writing the code. When writing a new feature, we should prioritize the correct implementation of business rules. So our main focus will be the core function.
As the adapters can be easily switched, we can start writing the business logic with “dummy” adapters. If we take the register example once more, our first focus should not be the way we persist our users in the database.
We will start writing an adapter that simply stores the user in memory like this:
TypeScript
export class MemoryUserManager implements IUserManager {
private readonly usersByEmail = new Map()
findByEmail: async (email: string) {
return this.usersByEmail.get(email)
}
create(email: string, password: string) {
this.set(email, {email, password})
}
}Obviously, this adapter is not production-ready, but it will be enough for us to validate the business logic. Once this is validated, we can then move to the “real” adapter, which will store the data in a real database. This also proves quite useful as the database schema might evolve during the development of the feature. For example, we might need some extra field that we had not thought of initially. Instead of writing numerous migrations to handle those changes, we can write a single one once we know exactly which data we need.
And finally, once we have ensured that the core functionality works as expected (with real or dummy adapters), we can focus on exposing this and creating the new HTTP controller.
You might be wondering why I haven’t mentioned testing at all while talking about development, don’t worry, I’m coming to it.
Easier testing
As there are numerous understandings of the word “testing”, let’s clarify this first. Here, I am mainly going to focus on the tests written by the developers: the unit tests written during TDD or the regression tests written before fixing a bug.
I do not have any experiences on how this design pattern benefits (or not) on other kind of testing (like testing done by QA, or usability testing or any other kind of testing), but I’d be eager to have any feedback there.
Focusing the tests
As the code you write only covers a specific section of the logic, your tests will do the same.
So when you are testing the core function, for example, your tests only cover the application of the business rules. When you are testing the HTTP layer, you can only focus on checking that it accepts the correct HTTP verb, returns the correct status and so on.
Testing the core
If we take once again the register example, the tests for the register core function might look something like this:
TypeScript
describe('register', () => {
let adapters: Adapters
beforeEach(async () => {
adapters = await makeAdapters()
})
it('returns error RegisterError.email_already_used if there is already a user with this email', async () => {
await adapters.userManager.create('someone@example.com', 'super-secret')
const response = await register('someone@example.com', 'whatever-password', adapters)
assert.deepStrictEqual(response, {error: RegisterError.email_already_used})
})
it('returns error RegisterError.password_too_short if the password is less than 8 characters', async () => {
const response = await register('someone@example.com', 123, adapters)
assert.deepStrictEqual(response, {error: RegisterError.password_too_short})
})
it('creates the new user if the email is not used and the password is “strong” enough', async () => {
// …
})
})Testing the HTTP layer
And in another test file, we can write tests that will solely focus on the HTTP layer:
TypeScript
describe('POST /users/', () => {
it('returns a status 409 if the email is already used', async () => {
const response = request(
'POST',
'/users',
{email: 'someone@example.com', password: 'superSecret'}
)
assert.strictEqual(response.status, 409)
})
it('return a status 422 if the password is too short', async () => {
// ...
})
})Mocking or not mocking
For those tests, there are two different approaches:
- Write really unit tests that will only trigger the code in the HTTP controller: the core function will be mocked to return the expected responses
- Use the real core implementation behind
In fact, we could have done the same in the tests covering the core function: instead of using adapters, we could have mocked them.
For example, the test about email conflict could have been:
TypeScript
it('returns error RegisterError.email_already_used if there is already a user with this email', async () => {
adapters.userManager.findUserByEmail = mock(
async (email) => return ({email, password: superSecret})
)
const response = await register(
'someone@example.com',
'whatever-password',
adapters
)
assert.deepStrictEqual(response, {error: RegisterError.email_already_used})
})On the principle, I tend to find the first approach better. Using the full stack does not really make sense as each part is tested individually, and the business logic is retested multiple times.
Some limitations with mocking
In practice, I’m always a bit dubious about mocking. I dislike this practice because it can cause discrepancies between real implementation, and it’s mock after refactorings. And we might end up with tests that are still passing, although the full stack is failing.
Let’s take for example the following test:
TypeScript
it('return a status 422 if the password is too short', async () => {
register = mock(
async () => ({error: RegisterError.password_too_short})
)
const response = request(
'POST',
'/users',
{email: ‘someone@example.com’, password: 123}
)
assert.strictEqual(response.status, 422)
})In the future, if we decide to refactor the register core function and add new rules about password validation, there might be an issue where the error RegisterError.password_too_short is never returned by the register function. Despite this, the test would still pass, at least if we do not update the controller. However, it does not make any sense that the test would pass under these circumstances.
If we were using TypeScript, we might get some build error saying that RegisterError.password_too_short does not exist anymore, provided that we didn’t forget to drop it from the RegisterError. But without a typed language, we might never notice the problem. When I was working with a Ruby backend, I tended to distrust some of the tests due to this false positive and the fact that we didn’t get any warning about differences between the mocks and the real implementation.
So in general, I tend to use the full stack and avoid mocking, except in a few cases:
- when we require an external service
- when the setup needed to get to a particular case is too tedious to write
- when the underlying logic takes “too long” to be executed
The notion of a test-taking “too long” to execute is dependent on the developer’s patience and the complexity of the core functions. In practice, what generally takes the most time in the tests is querying the databases. Thanks to the hexagonal architecture, we have an easy way to handle this.
Contract testing and speeding up tests
All our adapters are exposed as implementing a single interface. This allows us to have multiple implementations of the same adapter sharing a single test suite, ensuring that they behave the same way.
For example, let’s have a look at what the tests for UserManager may look like:
TypeScript
function IUsermanagerContractTest(
implementationName: string,
makeAdapter: () => IUserManager
) {
describe(`IUsermanager: ${implementationName}`, () {
let adapter: IUserManager
beforeEach(() => {
adapter = makeAdapter()
})
describe('findByEmail', () {
it('returns null if there is no user with this email', async () => {
const user = await adapter.findByEmail('whatever@example.com')
assert.strictEqual(user, null)
})
it('returns the user which matches the email', async () => {
await adapter.createUser('someone@example.com', 'secret')
const user = await adapter.findByEmail('someone@example.com')
assert.deepStrictEqual(user, {email: 'someone@example.com'})
})
})
})
}Contract Testing and Adapter Implementation for Quicker and Safer Testing
We can have two adapters: one storing data in a database, and the other in memory. Like the “dummy” adapters mentioned earlier.
Thanks to the contract test, we know that both implementations work exactly the same way and can be interchanged (well, except for the persistence, obviously). So we can safely run our tests using the memory adapters, which are way quicker. For our backend, we have now two different test targets:
npm run quick-tests: only use memory adapters, exclude all tests about adapters relying on the database and performance testsnpm test: run all the tests and uses by default the production adapters (using database)
Running only the quick tests takes about 45 seconds on my machine (for almost 800 tests), running the complete suite takes about 8 minutes, for about 950 tests. So it’s rather obvious which target I am going to run before pushing to the remote repository.
And contrary to the mocks I mentioned earlier, I still have confidence that the tests passing with the dummy adapters will also pass with the database ones. We may encounter discrepancies in adapter behavior, such as differences in how items are sorted during querying. If such discrepancies arise, the solution is to create a new contract test that specifies the expected behavior and ensures consistency across all adapters.
Fewer ties with infrastructure and tools
Having adapters that decouple the business logic from the external tools makes changing tools easier. These external tools may include databases, emailers, loggers, monitoring tools, and so on.
I will not lie, in saying that migrating from a relational database to a no-SQL one is done in the blink of an eye. Of course, this may take time. It may not be straightforward to do this with zero downtime. However, at least you have a limited amount of code to update, as all the database-related code is limited to the adapters.
Even without changing the entire database, it can be nice to have the choice depending on the data that are stored. Certain data may not require permanent storage and could be stored more efficiently in Redis with expiration settings. Only the adapter managing this type of data will have to be updated.
As a real-life example of this, we currently store all our data in a single relational database. The database contains approximately 4 million entries, with our collector tracking around 3.5 million entries related to actions. Today, our database is perfectly capable of handling the load of data, but we might have to turn to another tool in the future. If this day comes, we know we will only have one adapter to update to transition to the new database.
Flexible and Scalable Architecture for External Services in Code and Operations
This flexibility against other tools does not of course limit to databases. Any external service can be more easily switched with minor impacts on the code. For example, most applications will rely somehow on a few to contact users by email. The most straightforward way to do it when starting is to use SMTP. Once when the user base starts growing, the marketing team might want to use other tools to reach users. Those tools might not expose an SMTP server, but some API endpoint instead.
When all emailing is handled by an adapter, all you have to do is to create a new implementation of this adapter. You can roll out the new tool progressively while keeping the previous implementation available to most users.
If we unzoom a bit from the code itself, this approach can also provide some benefits at the operational level. Traffic mainly comes from the collector, which gathers user action data. We are currently running on a single Express server, and it can take the load. But in the future, with more users and more web applications monitored, the traffic on this endpoint may degrade the usability.
It would be fairly easy to move this endpoint to another server or to move it to AWS Lambda (or any other equivalent platform) for scalability. This is because the core of this endpoint is decoupled from the Express server itself.
To conclude about Hexagonal Architecture
I wish I had a time machine and discovered this pattern way earlier. It is now about three years since I apply Hexagonal Architecture to most of the code I’m writing. I could have avoided so many painful moments. The emailing changes is based on a real-life example, and it took way more time than it should have done :D.
One thing that I have not mentioned is that this pattern can also fairly well integrate with an existing code base. When I joined the team, the backend controllers were contained various levels of logic, a bit like the code sample at the beginning of this post.
In order to convince the rest of the team that we should use another approach, I did not go to a big-bang solution and rewrite all that existed. Instead, we started using this design pattern on the newly created controllers. Once the team was convinced that this approach was useful, we started refactoring the existing code to follow this new pattern. Instead of rewriting all at once, we took our time to refactor one controller at a time, until there were no monolithic controllers left. It took a few months, but those small steps allowed us to keep delivering new features. We took a brand-new approach, which prevented us from halting for weeks.

Stay tuned!
AI and E2E/Regression Testing: How to Maintain Business Control?
AI Testing Yest
Designing good tests requires a strong understanding of the business. This is why QA teams, among all…
Read the article

Can We Trust an AI Agent to Execute Tests?
AI Lynqa
The three pillars of trustworthy agentic AI test execution in Xray: measurable reliability, human control, and transparent…
Read the article

AI Test Automation in Xray: Two Ways, Two Benefits, One Lifecycle
AI Lynqa
“AI for test automation” covers several very different things. In the Jira/Xray ecosystem specifically, two approaches are…
Read the article