









IA et self-healing des tests : vraie fausse bonne idée ?
Actualité AI Lynqa


Génération, self-healing… et conservation de l’intention métier
L’intelligence artificielle transforme rapidement le monde du test logiciel. Après avoir longtemps été utilisée principalement pour l’analyse ou la génération de données, elle s’invite désormais dans toutes les étapes du cycle de test : génération de cas de tests, maintenance automatisée, exécution autonome, analyse des résultats, priorisation des campagnes, etc.
Parmi ces usages, l’exécution des tests est probablement un des domaines où l’impact est le plus espéré. Pourquoi ?
Parce qu’il concentre historiquement les principaux irritants des équipes QA : fragilité des scripts, coût de maintenance élevé, dépendance à l’implémentation technique, et difficulté à maintenir les tests alignés avec les besoins métier.
Deux approches émergent aujourd’hui autour de l’IA pour résoudre ces problèmes :
- la génération automatique de scripts de tests,
- le self-healing des scripts existants.
Mais ces approches soulèvent aussi une question fondamentale : jusqu’où peut-on automatiser la correction d’un test sans perdre son intention initiale ?
Génération de scripts de tests par l’IA
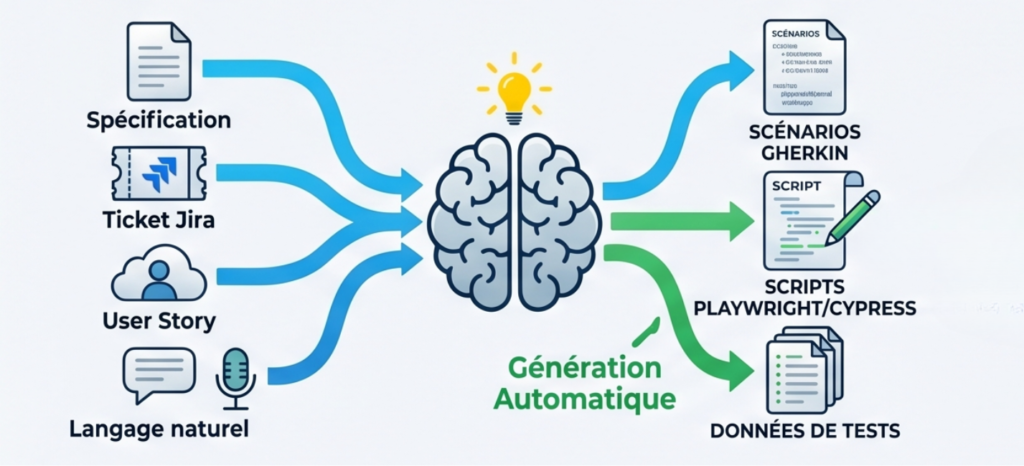
La première grande promesse de l’IA appliquée au test est la génération automatique de scripts.
À partir d’une spécification, d’un ticket Jira, d’une user story ou même d’une description en langage naturel, les modèles d’IA sont capables de produire :
- des scénarios Gherkin,
- des scripts Playwright, Cypress ou Selenium,
- des données de tests,
- voire des suites complètes de validation.
L’objectif est clair :
- accélérer la création des tests,
- réduire la barrière technique,
- démocratiser l’automatisation.
Cette approche apporte une vraie valeur, notamment dans les phases initiales d’un projet ou pour couvrir rapidement un périmètre fonctionnel large.
Mais une fois les scripts générés, un problème bien connu réapparaît : la maintenance.
Le self-healing : réparer automatiquement les tests
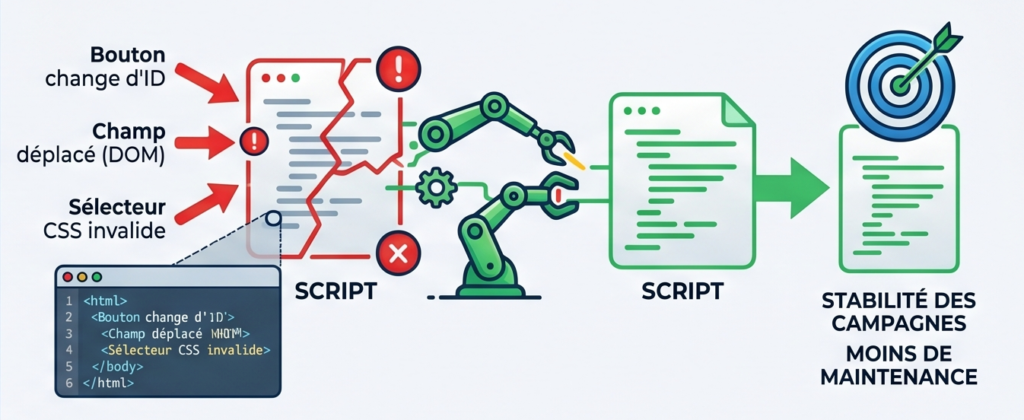
Les outils de self-healing proposent de résoudre ce problème en utilisant l’IA pour adapter automatiquement les scripts lorsque l’application évolue.
Exemples classiques :
- un bouton change d’identifiant,
- un champ est déplacé dans le DOM,
- une structure HTML évolue,
- un sélecteur CSS devient invalide.
Plutôt que de faire échouer le test, l’outil tente de :
- retrouver l’élément “le plus probable”,
- modifier le sélecteur,
- mettre à jour le script automatiquement.
Sur le papier, le gain est considérable :
- moins de faux négatifs,
- moins de maintenance manuelle,
- plus de stabilité des campagnes.
Le self-healing répond donc à un vrai besoin opérationnel.
Mais cette approche pose une question essentielle.
Corriger un test à partir de l’implémentation : un risque de dérive ?
Quand un moteur d’IA corrige automatiquement un script en observant l’interface ou le DOM, il se base principalement sur l’implémentation technique actuelle de l’application.
Autrement dit :
- le système sous test devient aussi la source de vérité permettant de corriger le test.
Et c’est là qu’apparaît une forme de paradoxe. Un test est censé vérifier qu’une implémentation respecte une intention métier définie en amont.
Mais si le test s’adapte automatiquement à l’implémentation observée, sans validation explicite de cette intention, alors :
- le test risque progressivement de “suivre” l’application,
- même lorsque l’évolution introduit une régression fonctionnelle.
Le danger n’est donc pas uniquement technique.
Il est aussi sémantique :
- le test peut continuer à “passer”,
- tout en ayant perdu ce qu’il était réellement censé vérifier.
En d’autres termes :
un test auto-réparé peut devenir cohérent avec l’interface… mais incohérent avec le besoin métier initial. Le risque est alors de devenir à la fois juge, et partie…
Préserver l’intention du test
Cette problématique remet au centre une notion souvent sous-estimée : l’intention du test.
Pourquoi ce test existe-t-il ?
Quel comportement métier cherche-t-il réellement à valider ?
Quelle est la règle fonctionnelle derrière les clics et les sélecteurs techniques ?
Dans les approches classiques d’automatisation, cette intention finit souvent “compilée” dans une représentation intermédiaire :
- scripts techniques,
- sélecteurs,
- modèles DOM,
- actions Playwright/Selenium.
Le problème est que cette représentation devient progressivement la référence principale… alors qu’elle ne devrait être qu’un moyen d’exécution.
Une approche alternative : exécuter directement l’intention métier
C’est précisément l’approche que propose Lynqa.
Avec Lynqa, les tests restent exprimés en langage naturel ou en Gherkin, directement dans Xray.
L’IA ne cherche pas à :
- générer un script technique intermédiaire,
- ni à corriger automatiquement un code de test existant.
Elle interprète directement l’intention métier exprimée dans le scénario pour exécuter le test.
Cette différence est fondamentale.
Comme il n’existe pas de représentation technique persistante du test :
- il n’y a pas de script à “réparer”,
- pas de sélecteurs à maintenir,
- pas de divergence progressive entre le besoin métier et le code de test.
Le référentiel reste le scénario fonctionnel lui-même.
Ainsi :
- l’intention du test est conservée,
- le langage métier reste central,
- et l’IA agit comme un moteur d’exécution plutôt que comme un mécanisme de correction a posteriori.
Conclusion
L’IA ouvre des perspectives considérables pour l’automatisation des tests :
- génération accélérée,
- maintenance réduite,
- exécution plus robuste,
- meilleure accessibilité des outils QA.
Le self-healing représente une avancée importante pour réduire la fragilité des tests automatisés traditionnels.
Mais il soulève également une question fondamentale :
Un test qui s’adapte automatiquement à l’implémentation vérifie-t-il encore réellement le besoin métier initial ?
Préserver l’intention du test devient alors un enjeu majeur.
Et c’est probablement là que les approches centrées sur le langage naturel, comme Lynqa, apportent une rupture intéressante :
plutôt que de maintenir des scripts techniques, elles cherchent à exécuter directement l’intention fonctionnelle.
Cette notion de préservation de l’intention peut d’ailleurs devenir un véritable critère de choix entre automatisation classique et exécution via Lynqa.
Pour des tests très techniques, fortement couplés à l’implémentation ou nécessitant des validations précises de bas niveau, l’automatisation scriptée conserve tout son intérêt.
En revanche, pour des scénarios fonctionnels où l’objectif principal est de vérifier un comportement métier exprimé de manière lisible et durable, une approche comme Lynqa permet de conserver le test au plus proche de son intention initiale, tout en réduisant la dépendance aux détails techniques de l’interface.
Restez à l'affut des nouveautés
Testeurs, il est temps de vous équiper d’un IDE de test !
Actualité Test Yest
Le développement logiciel a connu d’innombrables révolutions au cours des deux dernières décennies. Avec l’avènement des méthodologies…
Lire l'article
IA et tests E2E/TNR : comment garder la maîtrise métier ?
Non classé
Concevoir de bons tests exige une forte connaissance métier. C’est d’ailleurs pourquoi les équipes QA sont souvent,…
Lire l'article

Yest & Model-Based Testing : les réponses aux questions que se posent les équipes IVVQ
Yest
Lors de notre webinaire avec Thales, une chose est apparue très clairement : les équipes de test…
Lire l'article